这篇文章主要讲解了“怎么将日志文件和二进制文件快速导入HDFS”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“怎么将日志文件和二进制文件快速导入HDFS”吧!
首选数据移动方法
如果在旧版Hadoop环境中运行,我们可能需要一些工具来移动数据,这些工具都会在本章介绍。如果使用Kafka作为数据传输机制,则允许将生产者与消费者分离,同时使多个消费者能够以不同的方式对数据进行操作。在这种情况下,我们可以使用Kafka在Hadoop上存储数据,并为实时数据流系统(如Storm或Spark Streaming)提供数据,然后使用它执行近实时计算。比如,Lambda架构允许以小增量实时计算聚合数据,并使用批处理层执行纠错和添加新数据点等,从而发挥实时和批处理系统的优势 。
实践:使用Flume将系统日志消息推送到HDFS
面对跨多个服务器的多个应用程序和系统生成的一堆日志文件,我们可能手忙脚乱。毫无疑问,从这些日志中可以挖掘出有价值的信息,但第一大挑战是将这些日志移动到Hadoop集群以便可以执行某些分析。
版本注意事项
此处的Flume使用版本1.4。与所有软件一样,不保证此处介绍的技术,代码和配置可以使用不同版本的Flume开箱即用。此外,Flume 1.4需要一些更新才能使其与Hadoop 2一起使用。
问题
希望将所有生产服务器的系统日志文件推送到HDFS。
解决方案
使用Flume(一种数据收集系统)将Linux日志文件推送到HDFS。
讨论
Flume的核心是日志文件收集和分发,收集系统日志并传输到HDFS。此技术的第一步涉及捕获附加到/var/log/messages的所有数据并将其传输到HDFS。我们将运行一个Flume agent(稍后详细介绍),这将完成所有工作。
Flume agent需要配置文件指明该做什么,以下代码为用例定义了一个:
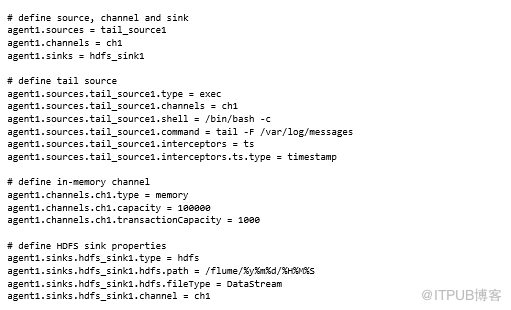
要让示例起作用,需要确保正在使用可以访问Hadoop集群的主机,以及 HADOOP_HOME配置正确,还需要下载并安装Flume并将FLUME_HOME设置为指向安装目录。
使用文件名tail-hdfspart1.conf将前面的文件复制到Flume conf目录中。完成后,就可以启动Flume agent实例了:

这应该会产生很多输出,但最终应该看到类似于以下的输出,表明一切都好了:

此时,应该看到HDFS中出现的一些数据:

.tmp后缀表示Flume打开文件并继续写入。一旦完成,这将重命名文件并删除后缀:

可以捕获此文件以检查其内容,内容应与tail/var/log/messages对齐。
到目前为止,我们已经用Flume完成了第一次数据移动!
解析Flume agent
让我们回过头来检查一下做了什么。主要有两个部分:定义Flume配置文件,以及运行Flume agent。Flume配置文件包含有关源,通道和接收器的详细信息,这些都是影响Flume数据流不同部分的概念。图5.4显示了Flume agent中的这些概念。
让我们逐步介绍这些概念,包括用途以及工作原理。
Sources
Flume sources负责从外部客户端或其他Flume接收器读取数据。Flume中的数据单元被定义为一个事件,本质上是一个有效载荷和可选元数据集。Flume源将这些事件发送到一个或多个Flume通道,这些通道处理存储和缓冲。

图5.4 agent上下文中的Flume组件说明
Flume有一组广泛的内置源,包括HTTP,JMS和RPC。让我们来看看你设置的特定于源的配置属性:

exec source允许执行Unix命令,标准输出中发出的每一行都被捕获为事件(默认情况下会忽略常见错误)。在前面的示例中,tail -F命令用于在生成系统消息时捕获它们。如果可以更好地控制文件(例如,如果可以在完成所有写入后将它们移动到目录中),考虑使用Flume的假脱机目录源(称为spooldir),因为它提供了exec source无法获得的可靠性语义。
仅使用tail进行测试
不鼓励使用tail进行测试以外的任何操作。
郑重声明:本文版权归原作者所有,转载文章仅为传播更多信息之目的,如作者信息标记有误,请第一时间联系我们修改或删除,多谢。