本篇内容介绍了“Spark集群怎么部署”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!
本文将接受 Spark 集群的部署方式,包括无 HA、Spark Standalone HA 和 基于 ZooKeeper 的 HA 三种。
环境:CentOS6.6 、 JDK1.7.0_80 、 关闭防火墙 、 配置好 hosts 和 SSH 免密码、Spark1.5.0
一. 无 HA 方式
1. 主机名与角色的对应关系:
node1.zhch Master
node2.zhch Slave
node3.zhch Slave
2. 解压 Spark 部署包(可以从官网直接下载部署包,也可从官网下载源码再
编译出部署包)
[yyl@node1 program]$ tar -zxf spark-1.5.0-bin-2.5.2.tgz
3. 修改配置文件
说明:
SPARK_MASTER_IP :Master节点地址
SPARK_MASTER_PORT :Master端口号
SPARK_WORKER_CORES :每个worker的核心数,一般设置成主机的CPU核心数
SPARK_WORKER_INSTANCES :每台主机上运行的worker数量
SPARK_WORKER_MEMORY :Spark作业允许使用的内存总量(每个作业自己的内存空间由属性 spark.executor.memory 决定)
4. 分发 Spark
[yyl@node1 program]$ scp -rp spark-1.5.0-bin-2.5.2 node2.zhch:~/program/
[yyl@node1 program]$ scp -rp spark-1.5.0-bin-2.5.2 node3.zhch:~/program/
5. 启动与停止命令
./sbin/start-master.sh - 启动 Master
./sbin/start-slaves.sh - 启动所有的 Slave
./sbin/start-slave.sh spark://IP:PORT - 启动本机的 Slave
./sbin/start-all.sh - 启动所有的 Master 和 Slave
./sbin/stop-master.sh - 停止 Master
./sbin/stop-slaves.sh - 停止所有的 Slave
./sbin/stop-slave.sh - 停止本机的 Slave
./sbin/stop-all.sh - 停止所有的 Master 和 Slave
./bin/spark-shell --master spark://IP:PORT - 运行 Spark Shell
./bin/spark-submit --class packageName.MainClass --master spark://IP:PORT path/jarName.jar - 提交作业
二. Spark Standalone HA
只需要在无 HA 的基础上修改 conf/spark-env.sh 文件,添加如下一行即可:
说明:
spark.deploy.recoveryMode -- FILESYSTEM,表示开启基于文件系统的单节点恢复模式 ,默认为 NONE
spark.deploy.recoveryDirectory -- Spark 保存恢复状态的目录
三. 基于 ZooKeeper 的 HA
1. 主机名与角色的对应关系:
node1.zhch Master、ZooKeeper
node2.zhch Master、ZooKeeper
node3.zhch Slave、ZooKeeper
node4.zhch Slave
node5.zhch Slave
2.
安装 ZooKeeper 集群
3. 配置
与无 HA 模式相比,conf/slaves 文件中仍然是配置所有的 Slave 节点地址;不同的是 conf/spark-env.sh 中 SPARK_MASTER_IP 不用配置,但要增加 SPARK_DAEMON_JAVA_OPTS 配置,内容如下:
说明:
spark.deploy.recoveryMode -- ZOOKEEPER,表示开启基于 ZooKeeper 的 HA
park.deploy.zookeeper.url -- ZooKeeper URL
spark.deploy.zookeeper.dir -- ZooKeeper 保存恢复状态的目录,缺省为 /spark
配置好 HA 后,由于 master 有多个,在用到 spark url 的地方列出所有的 master,例如:
./bin/spark-shell --master spark://host1:port1,host2:port2,host3:port3
5. 验证 HA
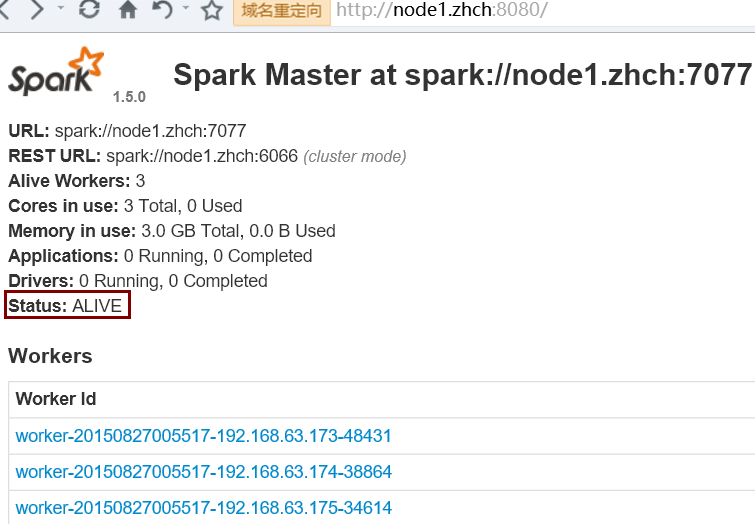
首先启动 Zookeeper 集群;然后在 node1 节点上运行 sbin/start-all.sh 命令启动 Spark 集群。最后使用 jps 命令查看,只在 node1 节点上发现了 Master 进程,而 node2 节点上没有,这时需要在 node2 节点上使用 sbin/start-master.sh 命令来启动备 Master 进程,这样便实现了 Master HA
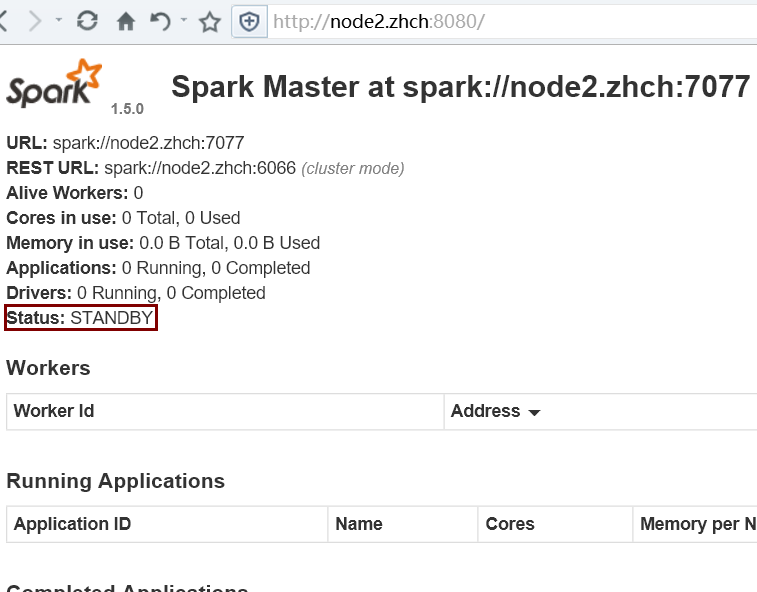
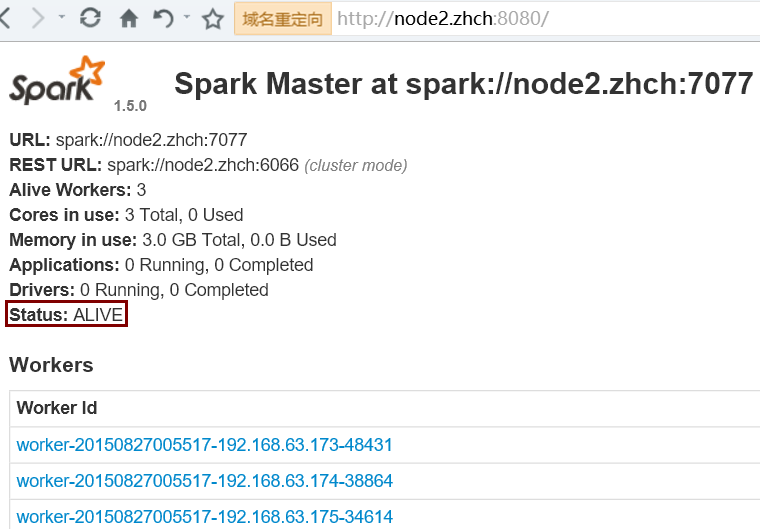
kill 掉 node1 节点上的 master 进程后:
郑重声明:本文版权归原作者所有,转载文章仅为传播更多信息之目的,如作者信息标记有误,请第一时间联系我们修改或删除,多谢。