Internet建立在一个非常简单的前提上:共享通信链接比大部分时间都处于空闲状态的专用通道更有效。
所以我们分享。我们共享工作中的局域网和家中的邻里链接。然后我们再次共享——在任何给定的时间,数以千计的人在网上冲浪、下载视频和通过互联网电话交谈时共享一条 TB 骨干电缆。
但是,管理人们如何共享互联网容量的协议存在严重缺陷。该协议让你看起来很有礼貌,即使你把别人推到一边,比他们占用的资源多得多。
Verizon 和 BT 等网络提供商要么在问题上投入容量,要么即兴设计试图惩罚所谓的带宽占用者的公式。让我马上为这个饱受诟病的野兽发声:带宽占用不是问题。没有必要阻止客户下载大量材料,只要他们不让其他人挨饿。
我和我在 BT(前身为英国电信)的同事并没有解决问题,而是想出了如何解决根本原因:互联网的共享协议本身。事实证明,这个解决方案不仅会使互联网更简单,而且速度也会更快。
您可能会惊讶地发现 Internet 的设计者打算将您的 Internet 容量份额取决于您自己的软件认为公平的程度。它们让网络运营商在 Internet 主机(现在超过 10 亿台个人计算机、移动设备和服务器)的冲突需求之间没有中介作用。
Internet 的主要共享算法内置于传输控制协议中,这是您自己计算机上大多数程序运行的例程——尽管它们不是必须的。TCP 是互联网的两大支柱之一,另一个是互联网协议,它将数据包传送到特定地址。这两者通常被称为 TCP/IP。
您的 TCP 例程不断提高您的传输速率,直到数据包无法通过前面的某个管道——这是拥塞的明显迹象。然后 TCP 非常礼貌地将您的比特率减半。互联网上数十亿的其他 TCP 例程以相同的方式运行,在获取,然后给予的循环中,填充管道同时平等共享它们。这是一种惊人的全球性自我否定,就像两个人同时靠近一扇门时使用的“after you”协议一样——但自相矛盾的是,互联网版本发生在完全陌生的人之间,甚至是激烈的商业竞争对手之间,每次发生数十亿次第二。
商业风险几乎不可能更高。YouTube、eBay、Skype 和 iTunes 等服务都是根据它们能为您获取的互联网容量来判断的,运营商自己提供的互联网电话和电视服务也是如此。其中一些公司选择退出 TCP 的共享机制,但大多数仍然允许 TCP 控制他们获得的数量——大约每秒通过 Internet 的 200 000 TB 的 90%。
这种非凡的全球合作精神源于互联网的早期历史。1986 年 10 月,互联网流量持续超过可用容量——这是一系列所谓的拥塞崩溃中的第一个。当时的 TCP 软件不断尝试重传,加剧了问题,并导致每个人的吞吐量连续数小时直线下降。到 1987 年年中,时任劳伦斯伯克利国家实验室研究员的 Van Jacobson 在 TCP 的补丁中编写了一组优雅的算法。(为此,他于 2002 年获得了 IEEE 享有盛誉的 Koji Kobayashi 计算机和通信奖。)
Jacobson 的拥塞控制非常符合 Internet 的定义设计原则:流量控制委托给 Internet 边缘的计算机(使用 TCP),而网络设备只路由和转发数据包(使用 IP)。
近乎普遍的使用和学术认可的结合逐渐将 TCP 的容量共享方式提升到道德制高点,改变了工程师使用的语言。从一开始,同等利率不仅是“平等”,而且是“公平”。即使您不使用 TCP,如果您的协议不是“TCP 友好的”,您的协议也会被认为是可疑的——这是一个听起来很舒服的想法,意味着它消耗的比特率与 TCP 大致相同。

节流这个:节流试图通过限制重度用户 [中心] 来纠正今天的 TCP 系统 [左],但该技术错过了一个技巧。使用加权 TCP 共享 [右],轻用户可以超快地运行,因此他们可以更快完成,而重用户只是稍纵即逝,然后赶上。所有这些都可以在网络中没有任何优先级的情况下完成。
可悲的是,根据任何现实定义,每个数据流的相同比特率可能是极其不公平的。这就像坚持食品配给盒的大小必须相同,无论每个人多久回来一次或每次拿走多少盒。
考虑一个有 100 个客户的社区网络,每个客户都有一条每秒 2 兆比特的接入线路连接到一条共享的 10 Mb/s 区域链路。网络提供商可以使用如此细小的共享管道,因为大多数客户(假设 100 人中的 80 人)不会连续使用它,即使在高峰期也是如此。这些人可能认为他们不断点击浏览器并接收新电子邮件,但他们的数据传输可能只有 5% 的时间处于活动状态。
然而,也有 20 名重度用户不断下载,可能使用无人看管的文件共享程序。因此,在任何时候,数据都会流向大约 24 个用户——所有 20 个重度用户,以及 80 个轻用户中的 4 个。TCP 将 20 份瓶颈容量分配给重度用户,而仅给轻量用户 4 份。稍后,这 4 名轻度用户将退出,另外 4 名将接管他们的股份。然而,这 20 名重度用户仍将在那里领取他们接下来的 20 股。他们还不如有专用的电路!
它变得更糟。任何程序员都可以多次运行 TCP 例程以获得多个共享。这很像通过复制配给券来绕过食物配给系统。
这个技巧一直被认为是一种规避 TCP 规则的方法——第一个 Web 浏览器打开了四个 TCP 连接。因此,如果这种策略没有变得更加普遍,那就太了不起了。
许多这样的策略是通过无辜的实验演变而来的。以点对点文件共享为例——一种通过 Internet 交换电影的常用方式,这种方式占所有流量的很大一部分。它涉及一次从多个对等点下载文件。这种并行方案,有时也称为集群,到 2001 年已成为常规,内置于 BitTorrent 等协议中。
网络社区并没有立即将与多台机器的连接视为对 TCP 友好规则的规避。毕竟,每次传输都使用 TCP,因此每个数据流“正确”地获得了它遇到的任何瓶颈的份额。但是在多台机器上使用并行连接是一种新的自由度,在第一次编写规则时没有想到。公平应该被定义为人与人之间的关系,而不是数据流。
点对点文件共享暴露了 TCP 的两个缺点。首先,文件共享程序的活动频率可能是您的 Web 浏览器的 20 倍,其次,它使用的 TCP 连接数要多得多,通常是其 5 甚至 50 倍。因此,点对点所占用的互联网瓶颈份额是浏览器的 100 或 1000 倍。
回到我们的 100 名宽带客户:如果他们只是浏览网页和交换电子邮件,每个人几乎都可以享受 2 Mb/s 接入管道的全部好处——如果一次有 5 个客户处于活动状态,他们只会挤进入 10Mb/s 共享管道。但是,即使 20 个用户开始连续并行下载,TCP 算法也会让其他人的比特率骤降到每秒 20 千比特——比拨号更糟糕!问题不在于点对点协议;这是TCP的共享规则。
为什么服务提供商不能简单地升级那个吝啬的 10 Mb/s 共享管道?当然,不时需要一些升级。但作为解决共享问题的一般方法,增加容量就像往山上泼水一样。
想象一下两个相互竞争的 Internet 服务提供商,都拥有这种 80:20 的轻重用户组合。一家提供商将其容量翻了两番;另一个没有。但是 TCP 仍然以相同的方式分配升级器的容量。因此,曾经拥有微不足道的 20 kb/s 份额的轻度用户,现在获得了微不足道的 80 kb/s — 仍然比拨号好一点。但是现在,80 名轻型用户必须为远距离容量的四倍支付更多的费用,而他们几乎无法使用这些容量。在这种情况下,没有理性的网络运营商会升级——它会失去大部分客户。
但有大量证据表明互联网服务提供商正在继续增加容量。部分原因是政府补贴,特别是在远东地区。同样,在美国典型的弱竞争允许提供商通过更高的费用为持续投资提供资金,而不会失去客户的风险。但在欧洲常见的竞争性市场中,服务提供商不得不解决根本原因:共享容量的方式。
网络提供商通常不允许 TCP 将所有新容量直接提供给重度用户。相反,他们将自己的共享机制强加给他们的客户,从而克服了 TCP 破坏机制的最坏影响。对点对点客户的峰值时间比特率进行某种限制或“节流”。其他人将管道隔开,以防止重度用户侵占较轻的用户。您实际获得的 Internet 容量份额越来越多地是 TCP 与服务提供商分配方案之间这种争斗的结果。
有一个比战斗更好的解决方案。它可以让轻量浏览速度非常快,但几乎不会延长重度下载的时间。解决方案分为两部分。具有讽刺意味的是,它首先让程序员更容易多次运行 TCP——故意打破 TCP 友好性。
使用这种新协议传输数据的程序员将能够说“表现得像 12 个 TCP 流”或“表现得像一个 TCP 流的 0.25”。他们设置了一个新参数——一个权重——这样每当你的数据遇到其他人都试图通过相同的瓶颈时,你将获得 12 份或四分之一的份额。请记住,网络没有设置这些优先级。它是您自己计算机中的新 TCP 例程,它使用这些权重来控制它从网络中获取的共享数量。
在我论点的这一点上,人们通常会问为什么每个人都不会宣称他们每个人都应该承受巨大的压力。这个问题的答案涉及一个技巧,它让每个人都有充分的理由谨慎使用权重——我将在一分钟内掌握这个技巧。但首先,让我们检查一下这个方案如何确保我刚刚承诺的闪电般的浏览速度。
关键是将轻量级交互使用的权重设置为高,例如网上冲浪,而将权重设置为低重使用量,例如电影下载。每当这些使用发生冲突时,具有较高权重的流量(来自轻用户的流量)会走得更快,这意味着它们也将更快完成。然后,重流可以比其他方式更快地扩展回更高的比特率。这就是为什么大量流量几乎不需要再完成的原因。加权方案使用与餐厅经理相同的策略,他说:“立即下单,然后来为 12 人聚会服务。” 但是今天的互联网正好相反。
这将我们带到问题的第二部分:我们如何鼓励每个人都改变权重?这项任务意味着要应对通常被称为“公地悲剧”的事情。一个熟悉的例子是全球变暖,每个人都乐于追求对他们最好的东西——开灯、开大车——尽管这可能会通过二氧化碳和其他温室气体的积累对其他人产生影响。
在 Internet 上,重要的不是你下载了多少 GB,而是当其他人都在尝试做同样的事情时你下载了多少。或者,更准确地说,它是您下载的流量按当时的拥堵程度加权。让我们称之为您的拥塞量,以字节为单位。将其视为您在互联网上的碳足迹。
与 CO 2 一样,削减的方法是设定限制。想象一个世界,一些互联网服务提供商以固定价格提供交易,但每月提供拥堵量补贴。请注意,此限额不限制下载;它仅限制在拥塞期间持续存在的那些。如果你使用像 BitTorrent 这样的点对点程序连续下载 10 个视频,只要你的 TCP 权重设置得足够低,你就不会破坏你的津贴。在流量伴随着更高的权重出现的短暂时刻,您的下载量会减少。但最终,您的视频下载完成的时间不会比今天晚。
另一方面,您的 Web 浏览器会为其所有浏览设置较高的权重,因为大多数浏览都非常频繁,因此它不会占用您的大部分资源。当然,服务器群或重度用户可以购买更大的拥塞配额,而轻度用户可能会以较低的固定费用获得互联网访问,但拥塞额度很小。
但是有一个障碍。今天的互联网服务提供商无法设置拥塞限制,因为拥塞很容易被他们隐藏。正如我们所说,互联网拥塞旨在仅由边缘的计算机检测和管理,而不是由中间的互联网服务提供商检测和管理。当然,接收方确实将有关拥塞的反馈消息发送回发送方,网络可以拦截这些消息。但这只会鼓励接收者撒谎或隐藏反馈——您不必透露任何可能用作对您不利的证据。
当然,网络提供商确实知道它必须自己丢弃的数据包。但是一旦证据被销毁,追究任何人的责任就变得有些棘手了。更糟糕的是,大多数 Internet 流量通过多个网络提供商,并且一个网络无法可靠地检测到另一个网络何时丢弃数据包。
由于 Internet 服务提供商看不到拥塞量,因此某些服务提供商限制了每个客户在一个月内可以传输的直接流量(以千兆字节为单位)。限制总流量确实有助于平衡一些事情,但限制拥塞量做得更好,为轻度用户提供极快的连接,而对重度用户没有实际成本。
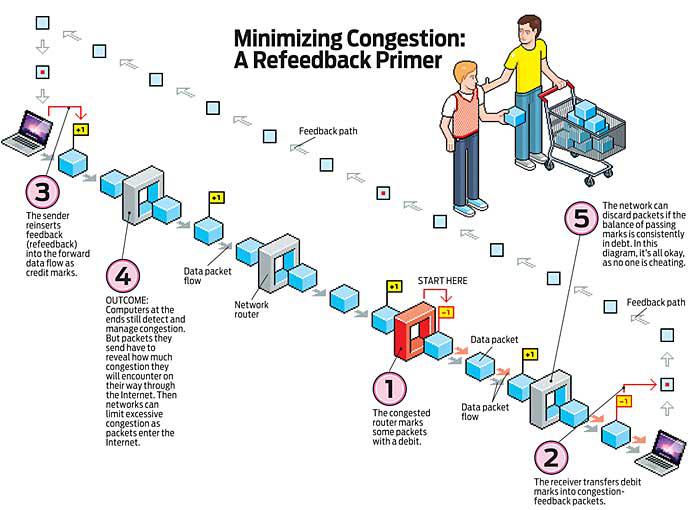
我和我的同事已经找到了一种揭示拥塞情况的方法,以便可以执行限制。我们称之为“再反馈”[参见“最小化拥塞:再反馈入门”.”]。这是它的工作原理。回想今天,数据包交换两端的计算机会看到拥塞,但它们之间的网络却不能。因此,我们构建了一种称为显式拥塞通知的技术——TCP/IP 标准的最新更改,于 2001 年进行。实现该更改的设备在即将发生拥塞时标记数据包,而不是在被迫丢弃数据包之前什么都不做。标记——只是一个位的变化——让网络直接看到拥塞,而不是从数据包流中的间隙推断它。能够在任何人遭受任何实际损害之前限制拥塞也特别巧妙。
尽管 2001 年的改革揭示了拥塞,但当数据包离开网络时,它只在任何瓶颈的下游可见。我们的再反馈方案使拥塞在上游网络进入互联网之前对上游网络可见,在那里它可以受到限制。
Refeedback 引入了第二种类型的数据包标记——将它们视为信用,将原始拥塞标记视为借方。发送方必须为进入网络的数据包添加足够的信用,以覆盖因数据包挤过拥挤的 Internet 管道而引入的借记标记。如果任何后续网络节点检测到相对于借记的信用不足,它可以丢弃来自违规流的数据包。
为了避免这种麻烦,每次接收方获得拥塞(借方)标记时,它都会向发送方返回反馈。然后发送方用信用标记下一个数据包。这种重新插入的反馈或重新反馈可以在互联网入口处使用以限制拥塞——您必须披露所有可能用作对您不利的证据。
Refeedback 坚持互联网原则,即网络边缘的计算机检测和管理拥塞。但它使网络中间人能够惩罚他们提供错误信息。
对于网络运营商来说,互联网边界的拥塞限制和检查是微不足道的。否则,再反馈方案不需要向网络设备添加任何新代码;它所需要的只是打开标准的拥塞通知。但是数据包需要在某个地方携带 TCP/IP 公式的“IP”部分中的第二个标记。幸运的是,这个标记是可以做的,因为每个 IP 数据包的头部都有最后一个未使用的位。
2005 年,我们准备了一份记录所有技术细节的提案,并将其提交给负责监督互联网标准的机构互联网工程任务组 (IETF)。
在这一点上,故事变得个人化。因为我给自己设定的任务是挑战 TCP 友好的根深蒂固的原则——所有 TCP 连接的流量相等——我决定只讨论对 IP 的改变,省略任何提及加权 TCP 的内容。相反,我提出了为 IP 添加重新反馈的一些其他动机。我什至展示了再反馈如何强制执行相等的流量——迎合观众的信仰,同时否认我自己的信仰。但我看起来就像又一个疯狂的研究人员在推动一个没有问题的解决方案。
在用头撞墙一年后,我写了一篇愤怒但——我相信——准确攻击相等流速是“公平”的教条。在我将其发布到 IETF 之前,我的同事让我对其进行了缓和;显然我已经足够软化它,至少在 2006 年底被邀请在圣地亚哥举行的全体会议上展示我的想法。的公平性。互联网架构委员会的 Elwyn Davies 给我发了电子邮件,说:“你在 IETF 中发现了一个真正的近视。”
我并不是第一个挑战这些神话的人。1997 年,剑桥大学教授弗兰克·P·凯利 (Frank P. Kelly) 汇集了一些令人惊叹的优雅简洁的数学论证,以证明相同的加权共享将使用户从互联网吞吐量中获得的价值最大化。然而,为了创造正确的激励措施,他提议在收到数据包时改变其收取的价格,但每个人都拒绝了。人们喜欢预先控制他们将支付的费用。
对凯利定价方案的反对使互联网社区对他工作中的所有其他见解视而不见——特别是均衡流量不是一个理想目标的信息。这就是为什么我的团队围绕他早期的想法建立了再反馈机制 - 在没有动态定价的情况下限制固定费用内的拥堵。
每个人随后对带宽的痴迷,因此对音量的痴迷,也被误导了。重要的是拥塞量——互联网的 CO 2。
同时,我们的当务之急是赢得互联网社区的支持,以限制拥塞,并为 IETF 的标准工作组揭示互联网隐藏的拥塞。选择的机制可能是重新反馈,但如果出现更好的东西,我不会生气,只要它使互联网变得如此简单和快速。
关于作者
BOB BRISCOE 描述了如何通过改造我们共享带宽的方式来缓解互联网拥塞。他说问题不在于带宽占用,而在于互联网的共享协议本身。Briscoe 是英国 BT 网络研究中心的首席研究员。他正在与 Trilogy Project 合作修复 Internet 的架构。
郑重声明:本文版权归原作者所有,转载文章仅为传播更多信息之目的,如作者信息标记有误,请第一时间联系我们修改或删除,多谢。




{kind=link}